Document Capture Through Intelligent Learning and Analytics
One of our regional reps produced this video to help show how we differ from other document capture and analytics platforms on the market. This is a great expansion to one of my earlier posts – Analytics and Document Capture – Why it Matters The video gives a great overview on the many dimensions of a document, and how Ephesoft leverages its patented technology to enhance accuracy, analyze large volumes of documentation, and process unstructured information.
Leveraging Intelligent Capture to Break Down Repository Silos
Every organization has them in both their technical realm and organizational/departmental structure: the Old Silo. But the elephant in the room is usually the document repository. That terabyte nightmare no one wants to address for fear of what lies within. Compounding the issue is the fact that most organizations have numerous document silos, usually the result of years of acquisitions, changing technical staffs with new ideas, or new line of business systems that house their own documents. Repository silos usually take the form of one of the below:
The File Share – when was the last time someone looked at that behemoth? Usually laden with layer upon layer of departmental and personal folder structures, a complete lack of file naming standards, and a plethora (my $2 word 😉 ) of file types. They continue to be backed up, and most IT departments that initiate projects for cleaning these up find a minefield, and departments that are fearful to purge anything
The Legacy ECM System – Hey, who manages Documentum/FileNet now?Do I continue to put items in X?How do I change the metadata in Y? As time goes on, legacy Enterprise Content Management becomes a huge burden on IT staff, and impose a massive cost burden for maintenance, support and development. Many of these systems were put in place a decade or so ago, and the file tagging and metadata needs have changes, with users struggling to find what they need through standard search. Some of these systems have just become expensive file shares, due to lack of required functionality or non-supported features.
The Line of Business Repository – just about every system nowadays has a “Document Management” plugin: the Accounting System that stores invoices, the Human Resource Info System that houses employee documents, or the Contracts Management system in legal that maintains contracts. These “niche” systems have created document sprawl within organizations, and a major headache for IT staff.
The SharePoint Library – The SharePoint phenomena hit pretty hard over the last 8 or so years, and most organization jumped on the train. Although most organizations we see in the field did not truly standardize on SharePoint as their sole repository, many started using it for niche solutions, focused on departmental document needs. Now, many years into their usage, they have massive content databases housed on expensive storage.
The New Kids on the Block – now enter the new kids: Alfresco, Dropbox, Box, OneDrive and Google Drive. New is a relative term here, but organizations now have broad and extensive content on cloud-based, file-sync technologies. Spanning personal and business accounts, these technologies have created new silos and management challenges for many organizations.
So, how can we leverage intelligent document capture and analytics to breakdown silos and make life easier? Here are some core “silo breaking” uses:
Data Capture and Extraction – for projects where you want to “peer” into that document repository and extract and/or analyze the content, there are two solutions. Intelligent capture applications, like Ephesoft Transact, can consume repository content, classify document types, and extract pertinent data. Transact has a whole set of extraction technologies that can pull out valuable unstructured data:
Key Value Extraction – this method can parse document contents for information. Take for example a repository of patient records where you want to glean patient name and date of birth. This technology will look for patterns, and pull out required data.
Paragraph Extraction – lets say you want to find a specific paragraph, perhaps in a lease document, and then extract important information. So you can easily identify paragraphs of interest across differing documents, and get what you need.
Cross-section Extraction – say you want to process 10 years of annual reports and pull off a specific bit of data from a table. Say the liabilities number from the financial section. You can specify the row and column header, and pluck just what you need.
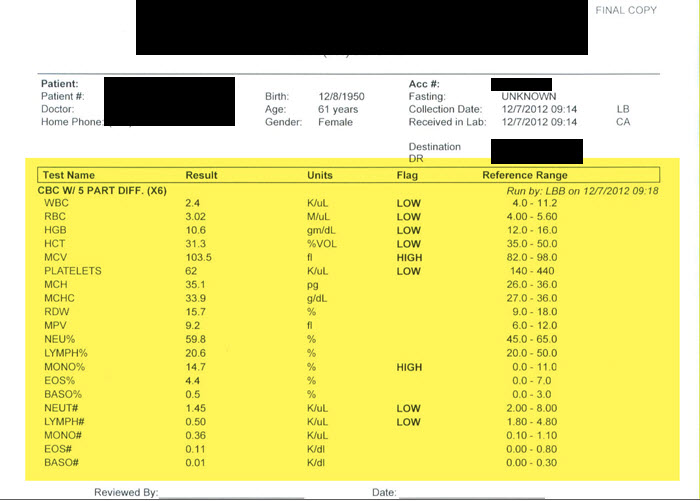
Table Extraction – what if you want tables of data within a repository of documents. Take for example lab results from a set of medical records. You can extract the entire table and export it to a DB across thousands of reports.
Extracting Lab Data with Capture
Managed Migration from X to Y – we are seeing the desire to consolidate repositories and drive “scrubbed” content to a new, central repository. Through advanced document capture, you can consume content from any of the above sources, reclassify, extract new metadata and confirm legacy data as you migrate to a new location.
Single Unified Capture Platform – providing a single, unified platform that can tie into all your existing repositories can save money, and add a layer of automation to older, legacy capture and scanning technology. This repository “spanning” strategy provides a single path for documents which enhances reporting, provides powerful audit capabilities, and minimizes support costs and IT management burden.
Advanced Document Analytics (DA) – with the advent of document analytics platforms, like Ephesoft Insight, you can make that repository useful from a big data perspective through supervised machine learning. These platforms take the integration of capture and analytics to the next level, and provide extensive near real-time processing. DA is focused on processing large volumes of documents and extracting meaning, where there seems to be absolutely no structure. So you can point, consume and analyze any repository for a wide variety of purposes. You can read some great use cases for this technology here: Notes From the Field: What’s Hiding in Your Documents.
Connecting the Dots with Document Analytics
Just a quick brain dump on breaking down silos with intelligent document capture and analytics. Thoughts? Did I miss anything?
I had dinner the other night with our CTO and our conversation was focused on why our technology was different, and what our Document Analytics patent brought to the table. Having been in the document capture industry for a long while, I was familiar with most of the technological “advances”. Things like automated extraction, pattern matching and classification through a variety of methods. I also knew with the acquisition craze, that much of the technology was for all intents and purposes, completely stagnant, with no true innovation for quite a while. In steps Document Analytics (DA).
First off, document analytics is part of Ephesoft’s core learning engine technology. So no matter your use case, the engine’s learning, multi-dimensional analysis and gleaned information are all available for use either through our end-user document capture application, platform APIs or our document analytics platform. So lets see what DA truly means.
Traditional document capture applications take digital documents, and if need be in the case of scanned images, do a conversion of the image to text through the process of Optical Character Recognition (OCR). This raw text can then be examined, and usually information is extracted based on simple location or a pattern match. This technique is great for simple data extraction, but when it comes to unstructured documents, without additional information, it can lead to erroneous data, and it can be quite limiting if you want a deeper understanding of your documents and data.
With document analytics, the goal is to gather multiple dimensions on not only your documents, but also what lies within. As you feed the learning system more documents, it learns continuously, and begins to gain understanding and predicting where key information is located. So lets look at all the dimensions a true document analytics engine can gather. Hold on, we are going full geek here.
Document Analytics Learns Document Dimensions
Root-stemming – most technology in the market looks at individual words on a page. True meaning comes in groups of words, and the analysis of their roots. Take for example an analysis of mortgage documents. the term borrower becomes extremely important, but unfortunately, when extracting data or searching for core data, you may encounter multiple forms: borrower, name of borrower, borrowed by, borrowing party, etc. Being able to identify a core root, borrow, and being tolerant of variations becomes extremely important, as does the ability to assign a confidence level to identified groups.
Relative Positions – gathering relative position information about words within a document can provide great insight. As we continue our borrower example, knowing that in the phrase “Borrowing Name” that name follows borrowing gives us insight, and helps in our quest for valuable data. Once again, this adds to our confidence that our data is being collected correctly.
Typographical Characteristics – understanding font, font size and other characteristics of words, can help us understand document structure. For example, a fillable PDF form we download from our medical insurance company will have a font for all the anchors: Patient Name, SSN, Address, etc. When we fill this form out, we enter our information with another font, perhaps in all capitals. This minor difference can provide meaning, and a better understanding of the structure of a document.
Value Identity – when analyzing documents, knowing conventions in data can aid in dimensional analysis. Take for example the social security number standard: NNN-NN-NNNN. Knowing this pattern, and using other dimensions, like position, can help us “learn” about documents. How? So, when we find this pattern on the page, we can look before it and above it to understand how it is identified. It would be prefaced by SSN, SSN:, Social:, SS Number, etc. Once we understand how SSNs are anchored, now we can understand how other data may be anchored as well.
Imprecision and Fuzziness – people are not perfect and neither is technology, and DA requires adaption to “imperfect” information. Take a zip code that is entered or read as 9H010. Well, we know that this data was prefaced by “Zip Code”, and we know they should be 5 numerical digits. We also know that an OCR engine can sometimes confuse a 4 and H depending on font type. Getting the drift here? By taking all our dimensions into account, we can say: this was locationally after “Zip Code:”, it is 5 characters, and I know sometimes 4 and Hs can be interchangeable for this font type. Therefore I can say with 90% confidence this is in fact a zip that had been misread or mis-entered.
Value Quantization – in gathering data, we know that certain words are most likely data that we will find interesting. Numbers (whole, 69010, or character delimited, 123-45-6789), dates (01/12/2001), and so forth are likely to be interesting data values that we need to extract, or will be required in our analysis. Taking this into account can help our confidence and accuracy.
Page Zones – in examining a document, certain areas, or zones, of a page usually contain important information. For instance, a contract will almost always have key participants in the top quarter of the first page. An invoice will have its total amount in the bottom half. Using this area analysis can help us identify key information, and add to our confidence in data extraction.
Page Numbers – As a human, I know that much of the important information will be on specific pages in documents I access on a day-to-day basis. But maybe a certain type of application has key information on page 3. Understanding and identifying core pages with critical data will provide added insight and aid in analytics.
Fixed Value Location – one key in learning documents is to examine and define text blocks of interest. Once these page areas are defined, the system can better understand layout and the design of document, and help predict where key data may be located.
This is just an overview of how we can make sense of unstructured information through advanced learning and analytics. If you want to go deeper, you can read the patent here: