Document Capture Through Intelligent Learning and Analytics
One of our regional reps produced this video to help show how we differ from other document capture and analytics platforms on the market. This is a great expansion to one of my earlier posts – Analytics and Document Capture – Why it Matters The video gives a great overview on the many dimensions of a document, and how Ephesoft leverages its patented technology to enhance accuracy, analyze large volumes of documentation, and process unstructured information.
Leveraging Intelligent Capture to Break Down Repository Silos
Every organization has them in both their technical realm and organizational/departmental structure: the Old Silo. But the elephant in the room is usually the document repository. That terabyte nightmare no one wants to address for fear of what lies within. Compounding the issue is the fact that most organizations have numerous document silos, usually the result of years of acquisitions, changing technical staffs with new ideas, or new line of business systems that house their own documents. Repository silos usually take the form of one of the below:
The File Share – when was the last time someone looked at that behemoth? Usually laden with layer upon layer of departmental and personal folder structures, a complete lack of file naming standards, and a plethora (my $2 word 😉 ) of file types. They continue to be backed up, and most IT departments that initiate projects for cleaning these up find a minefield, and departments that are fearful to purge anything
The Legacy ECM System – Hey, who manages Documentum/FileNet now?Do I continue to put items in X?How do I change the metadata in Y? As time goes on, legacy Enterprise Content Management becomes a huge burden on IT staff, and impose a massive cost burden for maintenance, support and development. Many of these systems were put in place a decade or so ago, and the file tagging and metadata needs have changes, with users struggling to find what they need through standard search. Some of these systems have just become expensive file shares, due to lack of required functionality or non-supported features.
The Line of Business Repository – just about every system nowadays has a “Document Management” plugin: the Accounting System that stores invoices, the Human Resource Info System that houses employee documents, or the Contracts Management system in legal that maintains contracts. These “niche” systems have created document sprawl within organizations, and a major headache for IT staff.
The SharePoint Library – The SharePoint phenomena hit pretty hard over the last 8 or so years, and most organization jumped on the train. Although most organizations we see in the field did not truly standardize on SharePoint as their sole repository, many started using it for niche solutions, focused on departmental document needs. Now, many years into their usage, they have massive content databases housed on expensive storage.
The New Kids on the Block – now enter the new kids: Alfresco, Dropbox, Box, OneDrive and Google Drive. New is a relative term here, but organizations now have broad and extensive content on cloud-based, file-sync technologies. Spanning personal and business accounts, these technologies have created new silos and management challenges for many organizations.
So, how can we leverage intelligent document capture and analytics to breakdown silos and make life easier? Here are some core “silo breaking” uses:
Data Capture and Extraction – for projects where you want to “peer” into that document repository and extract and/or analyze the content, there are two solutions. Intelligent capture applications, like Ephesoft Transact, can consume repository content, classify document types, and extract pertinent data. Transact has a whole set of extraction technologies that can pull out valuable unstructured data:
Key Value Extraction – this method can parse document contents for information. Take for example a repository of patient records where you want to glean patient name and date of birth. This technology will look for patterns, and pull out required data.
Paragraph Extraction – lets say you want to find a specific paragraph, perhaps in a lease document, and then extract important information. So you can easily identify paragraphs of interest across differing documents, and get what you need.
Cross-section Extraction – say you want to process 10 years of annual reports and pull off a specific bit of data from a table. Say the liabilities number from the financial section. You can specify the row and column header, and pluck just what you need.
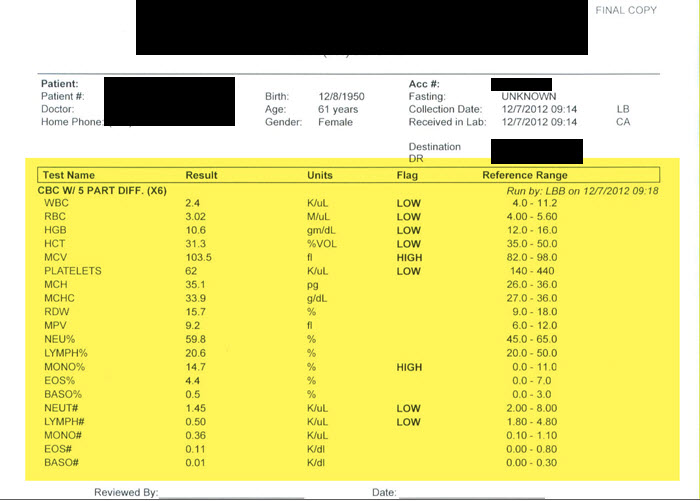
Table Extraction – what if you want tables of data within a repository of documents. Take for example lab results from a set of medical records. You can extract the entire table and export it to a DB across thousands of reports.
Extracting Lab Data with Capture
Managed Migration from X to Y – we are seeing the desire to consolidate repositories and drive “scrubbed” content to a new, central repository. Through advanced document capture, you can consume content from any of the above sources, reclassify, extract new metadata and confirm legacy data as you migrate to a new location.
Single Unified Capture Platform – providing a single, unified platform that can tie into all your existing repositories can save money, and add a layer of automation to older, legacy capture and scanning technology. This repository “spanning” strategy provides a single path for documents which enhances reporting, provides powerful audit capabilities, and minimizes support costs and IT management burden.
Advanced Document Analytics (DA) – with the advent of document analytics platforms, like Ephesoft Insight, you can make that repository useful from a big data perspective through supervised machine learning. These platforms take the integration of capture and analytics to the next level, and provide extensive near real-time processing. DA is focused on processing large volumes of documents and extracting meaning, where there seems to be absolutely no structure. So you can point, consume and analyze any repository for a wide variety of purposes. You can read some great use cases for this technology here: Notes From the Field: What’s Hiding in Your Documents.
Connecting the Dots with Document Analytics
Just a quick brain dump on breaking down silos with intelligent document capture and analytics. Thoughts? Did I miss anything?
Ephesoft has just released version 4.1 of our advanced capture platform, with a ton of new features. Below is just a quick list, you can watch the video below for more details:
Using Existing Data to Drive System Intelligence and Automation
This is part II in a series of videos showing Ephesoft’s Document & Process Machine Learning capabilities (Part I here: Machine Learning and Data Extraction) . In this video, I will show how you can add intelligence to any document capture process through learning external data tables. This allows for leveraging pre-existing ERP and financial system information to make the Ephesoft System smarter.
Intelligent Document Capture, OCR and Machine Learning
In my previous post, I outlined some of the premises of machine learning in document capture, and how it can drive unseen levels of efficiency and productivity (See here: Rise of the Machines: Machine Learning and Capture). I always like to follow-up with a video. This is the first of two videos focusing on Ephehsoft’s Machine Learning. This one is focused on end-user input driving document understanding for improved data extraction and less setup time.